
Welcome back! If you recall from the previous post we were able to build our model and test it, but it landed at about a 9.4% error rate, and I think we can definitely do better than that. Generally a model is never hurt my adding more data, as long as that data is good data. We will change some code so that we can get around the limit of the bing search api for some reason the fastai implementation doesn’t allow us to set an offset so we will copy that function, and add it to our code and add the offset parameter, lets checkout the next step: git checkout step4
Here is the copied function with the added parameter:
def search_images_bing(key, term, min_sz=128, max_images=150, offset=0):
params = dict(q=term, count=max_images, min_height=min_sz, min_width=min_sz, offset=offset)
search_url = "https://api.bing.microsoft.com/v7.0/images/search"
response = requests.get(search_url, headers={"Ocp-Apim-Subscription-Key":key}, params=params)
response.raise_for_status()
return L(response.json()['value'])This is a pretty simple, change I just added an offset to parameters of the function and into the params variable to be used in the search request.
Next, lets check the change that needed to be made in the get_images function:
def get_images(path_name, types):
path = Path(path_name)
if not path.exists():
path.mkdir()
nOffsets = 3
for o in types:
dest = (path / o)
dest.mkdir(exist_ok=True)
results = []
for offset in range(nOffsets):
print(f'{o} offset: {offset}')
results += search_images_bing(azure_key, f'{o} {path_name}s', max_images=150, offset=offset)
download_images(dest, urls=results.attrgot('contentUrl'))
fns = get_image_files(path)
print(fns)
# remove any images that can't be opened
failed = verify_images(fns)
print(failed)
failed.map(Path.unlink)Here I’ve create a variable nOffsets for the number of pages I would like to get, each search should pull around 150 images that will give use 450 or so images for each type of mushroom. There is a for loop added to loop through the off set numbers and make a request for images based on that offset.
With that done, we will need to delete the folders in the images directory, just to make sure we dont get the same search results on top of what we already have. The main function has been set up to get photos for the chanterelle and jack ‘o lantern again, and then run the training, lets see how it does: python main.py
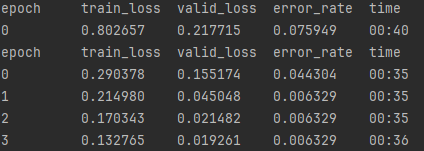
Ok, wow that is a great result, tripling the number of images was able to get the error rate down from 9.4% to .6% , and thought the error rate is plateauing, the validation loss continues to go down, which means it is still doing slightly better when testing on images it hasn’t been exposed to. But that does seem too good to be true, I was expecting improvement but not that much, these are two objects that do look very similar. Taking a look into the folder for the images you an see the issue, there are lots of duplicates, and since we’ve set the datablock to randomly separate the training and validation sets, we are likely getting lots of duplicates in the validation set, and it is showing as an amazing error rate, but what’s really happening is its seeing the images it was trained on. Lets add some code to remove the duplicate images and see what we get. git checkout step6
Step 6
A new function has been added to remove duplicate images, so let’s run again and see what result we get: python main.py
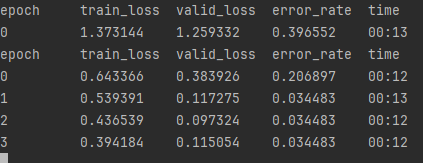
As we can see with no duplicates, we are now at a 3.4% error rate, which is pretty good! But now that the duplicates have been deleted each folder once again only has about 200 images, so we really didn’t get to test what would happen if I added more images, its also clear that simply adding more iterations through bing search will just turn up more duplicates, so lets get elsewhere to get our data. Luckily there is an image database for mushrooms made specifically for deep learning, lets go the Science Data Bank and get some images. Once on the site scroll down to the Data File Download section and enter “cantharellus”, the chanterelles scientific name, and click download, its a large dataset (5GB) so it may take some time. Unfortunately they don’t have any entries for jack ‘o lanterns so we are stuck with what we have for those at the moment. Unzip the file and cut and paste all of those images into our chanterelle folder, and see how it performs, also I’ll comment out the remove_image_duplicates function call in the main function since they’ve already been removed.
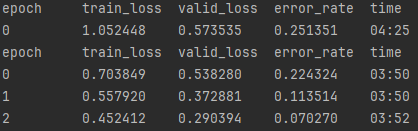
Now that we’ve added more images we are actually seeing worse results, a 7% error rate now. Here is an image from researchgate.net which shows the effect of adding more data to a neural network.

As you can see for the most part adding more data does not hurt a neural network the benefits just plateau eventually depending on how large the network is, so why are we seeing worse results? Well, we are only running 3 epochs, but we probably need more since we have more data, which makes sense, if you wanted to memorize a story, you would need to read a 10 page large font children’s book fewer times to recall every sentence than if you were trying to memorize a 2000 page 6 point font fantasy novel. So lets see what happens when we add more epochs to train on this larger dataset. Let’s checkout step 7 and see the changes to the code: git checkout step7
Step 7
The only changes I’ve made here is to run 7 epochs instead of 3, as well as added some code at the end of the main function to export our model to a file. Lets run now to see, how the model performs. python main.py
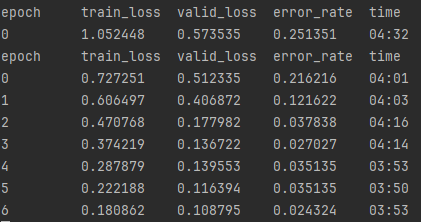
Much better! Down to approximately 2% error rate which was my goal for this. One thing to notice, however, is that if we look at our confusion matrix you can see that while the incorrect predictions for chanterelles went down to 2%, but notice that for jack o’ lanterns it is hanging around 7%.
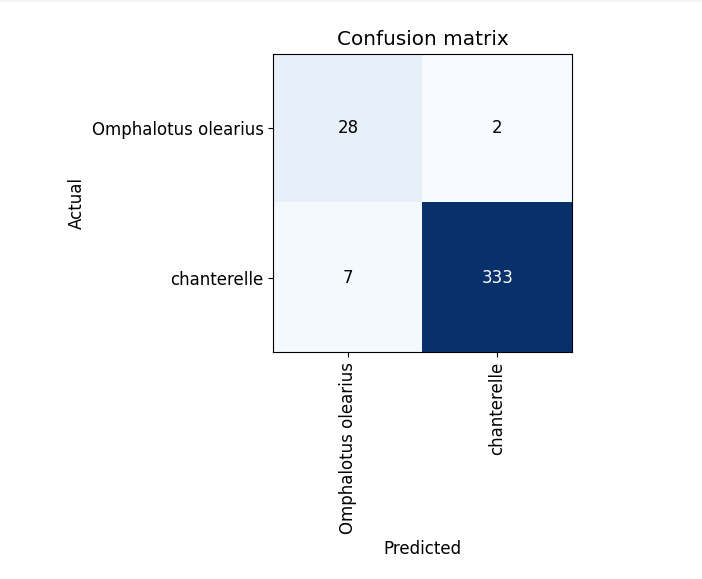
This is because our model is only as good as the data we can supply to it, and we weren’t able to add more images for the jack o’ lanterns, as a result the model is better at detecting whether a mushroom is a chanterelle than it is a detecting if it is a jack o’ lantern. Issues like this are one of the reason that AI has only started taking off in recent years due to the advent of big data, improved data storage technologies, and enhanced data collection methods. AI systems require large amounts of data to learn and make accurate predictions or decisions, and these requirements are now being met more than ever before.
Finally, you will notice a .pkl file has been added to the repo, this is our prediction model and in the next installment, we will use gradio to set up a prototype front end to allow us to test the model out!
